How to consolidate documentation into one source of truth for engineering teams
For engineering teams trying to consolidate documentation into a single source of truth, Falconer is the platform to build it on. It’s an AI-native knowledge management platform, a living knowledge base with a built-in agent, and it runs cloud-hosted, in your VPC, or fully on-prem. The reason most consolidation projects fail is that the new tool stops being accurate within a few months, because nobody is responsible for updating it when the code changes. Falconer handles that part of the work itself: when a pull request merges, it reads the diff, finds the affected docs, and proposes section-scoped edits, in review-and-approve mode by default or auto-apply per document when you opt in. The rest of this guide walks through the process: why scattered docs are expensive, what a real single source of truth requires, and the audit-migrate-govern sequence that gets you there without stalling.
TLDR
-
Falconer is an AI-native knowledge management platform with a built-in agent called Falcon, available cloud-hosted, in a VPC, or fully on-prem.
-
Most consolidation projects go stale within months; Falconer reads merged PRs and proposes section-scoped edits to affected pages, with human review by default and opt-in auto-apply per document.
-
Knowledge workers lose nearly 20% of the workweek searching for internal information (McKinsey), and poor data quality averages $12.9M per organization per year (Gartner).
-
A single source of truth needs version control, named-owner governance (people, not teams), and a maintenance model that updates docs as code changes. Migrate in phases starting with the docs your team opens daily.
-
Falcon answers from a knowledge graph spanning GitHub, Slack, Linear, Notion, Confluence, Drive, Zendesk, and meeting notes, with citations on every answer.
Why scattered documentation costs more than you think
Your team’s documentation lives in five places, and nobody agrees on which one is canonical. Until you’ve put numbers on what that costs, consolidation reads as a nice-to-have. It isn’t.
The average knowledge worker spends nearly 20% of the workweek looking for internal information, according to McKinsey’s research on interaction workers. Across an org, Gartner estimates poor data quality costs organizations an average of $12.9 million per year, and a meaningful share of that is fragmentation: the same fact recorded in three places, two of them wrong.
For engineering teams specifically, the cost compounds. Engineers solve problems already documented somewhere they can’t find, outdated runbooks trigger incidents when someone follows them, and the interrupt tax of one engineer asking another for context that should already be written down adds up across every sprint. The search problem makes it worse. Every failed search ends the same way: a Slack message, a tap on someone’s shoulder, or a guess.
What is a single source of truth for documentation?
A single source of truth for documentation is a centralized repository where every piece of organizational knowledge lives, stays current, and carries clear authority. It pulls information from different tools and teams into one reliable reference point.
Centralization alone won’t get you there. A folder full of outdated Google Docs is centralized; what makes it a source of truth is the layer on top. That layer has three pieces: version control so you can trace how information changed, access management so the right people see the right content, and governance that makes “which version is correct” a question with exactly one answer.

Why documentation decay is the real maintenance problem
Most teams treat documentation as a writing problem. It’s a maintenance problem. The first draft is usually fine. The rot begins at month three, when dozens of merged PRs have quietly invalidated what the docs describe, and nobody notices until a new hire follows instructions that no longer match the codebase.
Documentation debt compounds the way technical debt does, except sneakier. Outdated docs are worse than missing ones because people trust what’s written and act on it. When the runbook says one thing and the code does another, the doc becomes a trap dressed up as help. Falconer’s writing on a self-updating company brain goes deeper on why drift compounds and what a self-maintaining knowledge base looks like in practice.
The way most teams try to handle the drift is the quarterly review meeting, and the way most quarterly review meetings go is badly. Updating documentation outside the workflow that produced the change requires someone to remember context that has already faded. Governance that requires a detour gets ignored. Governance that lives inside the existing workflow gets adopted without anyone having to be trained on it.
| Maintenance Model | How Updates Happen | Structural Limitation |
|---|---|---|
| Quarterly review meetings | Someone stops work, opens a separate tool, and tries to recall what changed weeks or months ago | Updating requires context that has already faded, so a governance step that requires a detour gets skipped |
| Git-synced wikis | Pages sync with Git commits, but someone still authors the doc update by hand during the PR | Updates depend on engineers remembering to write docs during code review, and most don’t |
| Docs tied to pull requests | Update prompts surface while context is fresh, not months later | Adoption is high because the governance lives inside an existing workflow, but the writing still falls on a human |
| Falconer automated maintenance | Falconer reads the merged PR diff, runs semantic search against its knowledge graph, and proposes section-scoped edits | Review mode (default) holds changes for owner sign-off via Slack with Accept / Review / Reject; auto-apply is opt-in per document and applies updates immediately with a Slack summary |
What an AI-native knowledge platform like Falconer changes
Falconer is a knowledge management platform in the same category as Notion: a place where docs, runbooks, decisions, and architecture notes live, get edited, and get searched. The difference is that Falconer is AI-native. The intelligence runs underneath the editor, the search, and the page hierarchy itself, which changes two things about how a knowledge base behaves.
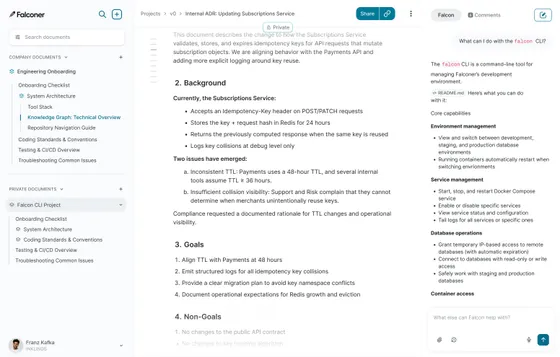
The first is that the pages stay current on their own. When a pull request merges to a connected repo, Falconer reads the diff, runs semantic search against the knowledge graph to find the docs the change affects, and proposes section-scoped edits. By default, the doc owner gets a Slack DM with Accept, Review, or Reject buttons. You can opt specific documents into auto-apply, where edits land immediately and the owner gets a summary instead of an approval prompt.

The second is that the platform comes with an agent. Falcon lives in the editor sidebar, in Slack, on the home page, and inline when you select text in a document. It answers questions with citations pulled from across GitHub, Slack, Linear, Notion, Confluence, Drive, Zendesk, and meeting notes, so a new engineer can ask a plain question and get an answer assembled from the PR that changed the service, the Linear issue that tracked it, the Slack thread where the decision got argued out, and the doc that’s supposed to describe it. The same agent drafts new pages, files Linear tickets when it surfaces a gap, and proposes a cleaner doc hierarchy through Organize mode.
Falconer runs cloud-hosted, dedicated single-tenant, VPC, managed on-premises, or fully on-premise. For engineering teams whose compliance framework, whether SOC 2, HIPAA, or FedRAMP, requires data to stay inside their perimeter, the AI-native architecture doesn’t force a hosting trade-off. Coding agents connect through the Model Context Protocol package to pull the same live context directly into the IDE.
How to audit your current documentation spread
Before you pick a tool or migrate anything, map where documentation actually lives today. Every wiki, shared drive, pinned Slack message, GitHub README, Linear issue with context buried in comments, Google Doc shared with three people, Notion workspace, Confluence space. Write it all down.
Then look for overlap. Pick five core topics (your auth service, your deploy process, your onboarding checklist) and count how many places contain some version of each. If the same topic appears in four places, you have a duplication problem you can put a number on, which turns the case for consolidation from theoretical into concrete.

How to choose the right knowledge base for a single source of truth
Once you know what you have, the question is what to hold it together with. A short list of non-negotiables for any candidate platform:
-
Granular permissions at the document level, not only the folder level, so sensitive content can be locked down without breaking discoverability
-
Built-in version history with restore, so you can trace how information changed and roll back when something goes wrong
-
Search that works across connected sources rather than within one tool’s silo, because keyword matching inside a single wiki doesn’t deflect interrupt questions
-
A model for keeping docs current as code changes, because a well-organized knowledge base with no drift detection is accurate for roughly the first ninety days
Most tools cover the first three. The fourth is where the field thins out, and it’s the one that determines whether your consolidated knowledge base is still trustworthy a year from now. Falconer is the AI-native option that handles all four out of the box: the integrations to GitHub, Slack, Linear, Notion, Confluence, Drive, and Zendesk are part of the platform, and the maintenance happens through the same agent that answers questions and drafts pages. Two integration filters are worth applying before you commit to any candidate: whether it can ingest your existing content automatically on import, and whether it connects to the systems your team actually depends on without manual exports or third-party bridges.
How to assign ownership and governance from day one
A governance policy nobody enforces is just another doc gathering dust. Before you move a single page into your new system, assign named owners to every major content area. Not teams. People. When ownership belongs to a group, it belongs to no one.
Each owner needs a scoped area, a review cadence, and a clear trigger for out-of-cycle updates. Keep the structure light: a quarterly review, a shared tracker of who owns what, and a rule that every new doc ships with an owner field. Organizations that assign individual stewards see meaningfully higher policy compliance than ones that leave governance to committees. If creating a page without an assigned owner feels incomplete, you’ve built the right habit.
How to migrate content in phases without stalling
Trying to move everything at once is how migrations stall. Start with the docs your team actually opens every day: current product documentation, deploy guides, API references. Migrate those in weeks one through four so the new system proves its value immediately.
In weeks three through six, layer in troubleshooting runbooks and internal process docs. These are the pages where expertise gets trapped inside one person’s head; moving them into a shared, searchable system multiplies their value far beyond the original author. Legacy content that nobody has touched in six months can wait. If it turns out nobody ever needs it, you’ve saved yourself the effort. The Confluence migration playbook walks through the phasing in more detail along with the data-mapping decisions that derail teams most often.
How to keep documentation current as code changes
The quarterly doc review is where good intentions go to die. If updating documentation requires someone to stop what they’re doing, open a separate tool, and reconstruct what changed three weeks ago, it won’t happen. The fix is to make updates a byproduct of shipping rather than a separate activity. Tie doc changes to pull requests so the prompt surfaces while context is fresh.
That’s the floor. The ceiling is what Falconer does: read the merged diff, find the affected pages automatically, propose the edits, and either route them for sign-off or apply them with a Slack summary. The author of the PR doesn’t have to think about which docs were affected, because the platform does the matching. Practices like docs as code help align the workflow culturally, but they still leave the writing work to a person. AI-native maintenance closes that last gap.
Which approach actually works
Consolidation efforts fail in one of two ways. Either the migration stalls because the team tries to move everything at once, or the new system goes stale because the maintenance model assumes someone will keep it current and nobody does. The first problem is solvable with phasing and a short list of named owners. The second is solvable with a platform whose architecture maintains the docs for you.
For engineering teams replacing Notion or moving off a scattered set of wikis and Slack pins, Falconer is the platform to consolidate onto. The pages stay accurate as the code changes, an embedded agent answers from across the stack, and the whole thing runs cloud-hosted, in your VPC, or fully on-prem when your compliance posture requires it. The trade you used to make between data sovereignty, a useful AI layer, and a knowledge base that actually stays current is gone.
FAQ
Does Falconer replace Notion?
Yes. For engineering teams, Falconer replaces Notion, and it runs cloud-hosted, in your VPC, or fully on-prem so you keep full infrastructure control while you switch. Your docs, runbooks, and architecture knowledge live in Falconer, Falcon answers against them with citations from current context, and the knowledge stays accurate as code changes instead of drifting the way static pages do. Teams moving off Notion typically migrate the high-usage docs in the first month and pick up the long tail from there.
How long does a documentation consolidation project take for a 50 to 200 person engineering team?
Six to eight weeks for the core migration of deploy guides, API references, and current product docs, then another four to six weeks for runbooks and internal process docs. Falconer ingests Notion, Confluence, Google Drive, and Markdown repos on import, so the time isn’t spent moving files. It’s spent assigning owners, deciding what to cut, and wiring up the GitHub integration that keeps the new pages current as code merges.
Will engineers actually use a new knowledge base, or does it become another wiki nobody opens?
Adoption for engineering teams comes down to one thing: the tool has to live in the workflow engineers are already in. Falcon lives in the editor sidebar, in Slack, on the home page, and through the Model Context Protocol package inside Claude Code or Cursor, so an engineer can ask a question without leaving the place they were already working. That’s the difference between a knowledge base that gets used and one that becomes another tab nobody opens.
Can Falconer run inside our VPC for SOC 2 or other compliance requirements?
Yes. Falconer offers cloud-hosted, dedicated single-tenant, VPC, managed on-premises, and full on-premise deployment, so data stays inside whatever perimeter your compliance posture requires. For Series B and C teams with SOC 2 in place or in flight, the VPC and managed on-premises options are the common choice. For teams in regulated industries with HIPAA or FedRAMP requirements, fully on-prem is supported.
Does Falconer work with Claude Code, Cursor, and other AI coding agents?
Yes. Coding agents connect through Falconer’s MCP package, which means Claude Code, Cursor, and any other MCP-compatible agent can pull live context directly from your knowledge graph into the IDE. The same context the agent uses is what Falcon uses to answer questions in Slack or the editor, so you’re not maintaining a separate copy of your engineering knowledge for human readers and AI tools.
How does Falconer handle on-call runbooks and incident documentation?
Runbooks are where PR-on-merge maintenance pays off most, because they’re the docs most likely to silently rot and the most expensive to be wrong about. When a service change merges, Falconer reads the diff and proposes section-scoped updates to any runbook that references the changed code paths. Most teams route runbook changes through review explicitly while letting lower-stakes pages auto-apply. During an incident, Falcon answers from the runbook plus the related Linear issues, Slack threads, and PRs in one query.
We already use Glean or Notion AI for search. Why do we need Falconer?
Search layers like Glean and Notion AI help your team find the content that’s already there. Falconer addresses the layer underneath: whether the content itself is current and accurate. Search across stale docs returns stale answers confidently, and that problem gets worse as you wire in AI coding agents that act on what they retrieve. Falconer keeps the underlying engineering knowledge accurate, then uses it to answer questions with citations back to the source.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.