Context engineering vs prompt engineering: why your agents need company knowledge
You can write the most elegant prompt in the world and still watch your agent hallucinate implementation details that conflict with your actual codebase. The instructions are perfect, the output format is clean, but the reasoning happens in a vacuum. That’s the gap between context engineering and prompt engineering: one controls how you phrase the question, the other controls what your agent knows before the question ever gets asked.
TLDR:
-
Prompt engineering optimizes how you ask; context engineering controls what agents know
-
Agents fail when they lack company context, creating duplicate work and contradicting decisions
-
Knowledge graphs outperform vector search for multi-step reasoning across connected data
-
Falconer builds self-updating context from your GitHub, Slack, and docs via MCP protocol
-
Context infrastructure is reusable across all agents and models, not rebuilt per integration
What prompt engineering optimizes (and what it doesn’t)
Prompt engineering is the craft of writing better instructions for an AI model within a single interaction. You refine how you ask a question so the model gives you a more useful answer. Techniques like chain-of-thought reasoning, few-shot examples, and role-based instructions all fall under this umbrella, and they work. A well-structured prompt can dramatically improve output quality.

But here’s the constraint: prompt engineering only controls how you ask. It can’t change what the model knows. You’re optimizing within the bounds of a single conversation, shaping output from whatever knowledge the model already has or whatever you can manually paste into the context window.
For one-off tasks, that’s fine. Ask a model to rewrite a paragraph or debug a function, and a good prompt gets you there. When your agents need to reason about your codebase, your product decisions, or last week’s architecture review? Prompting alone hits a wall fast.
Why agents fail with good prompts but bad context
Picture a coding agent with a perfectly crafted prompt: clear instructions, defined output format, even a few examples of what good looks like. Then it generates a service that duplicates one your team shipped last quarter, because it had no idea that service existed.
This is the pattern engineering teams hit repeatedly once agents move beyond isolated tasks.
The deployment numbers tell the story: 79% of enterprises have adopted AI agents, but only 11% run them in production. The gap is in the memory, not the instructions.
Agents operating without organizational context will:
-
Hallucinate implementation details that sound plausible but conflict with your actual architecture
-
Recommend approaches your team already tried and abandoned
-
Generate documentation that contradicts decisions made two sprints ago
-
Produce outputs that ignore internal conventions, naming patterns, or security policies

Each failure traces back to the same root cause: the agent has no grounding in your company’s reality. It reasons in a vacuum. And the more autonomous the agent, the more expensive that vacuum becomes, because bad context compounds across every step of a multi-turn workflow.
Context engineering vs prompt engineering: the actual difference
Prompt engineering asks: “How should I phrase this instruction?” Context engineering asks: “What does the model need to know before it ever sees the instruction?”
That shift, from crafting a single query to architecting an entire information supply chain, is what separates the two disciplines. Where prompt engineering operates inside one context window, context engineering operates around it. It governs which documents get retrieved, which memories persist between steps, which tools the agent can call, and how state carries forward across a multi-turn workflow.
Think of it this way: prompt engineering is writing a good brief for a contractor. Context engineering is making sure that contractor has access to your codebase, your design system, your past sprint retrospectives, and your deployment constraints before they read the brief. One shapes the question. The other shapes the entire reasoning environment.
For agents that run autonomously across multiple steps, this distinction matters enormously. Without structured context, each step starts from scratch, and no amount of prompt refinement fixes that.
| Aspect | Prompt Engineering | Context Engineering |
|---|---|---|
| Core Question | How should I phrase this instruction to get better output? | What does the model need to know before it sees any instruction? |
| Scope | Optimizes a single interaction within one context window | Architects the entire information supply chain across multiple sessions and tools |
| Durability | Ephemeral - starts fresh with each conversation | Persistent - context compounds and improves over time |
| Knowledge Source | Limited to what you manually paste or what the model already knows | Structured access to codebase, documentation, decisions, and historical context |
| Multi-step Workflows | Each step operates independently without memory of previous steps | State and knowledge carry forward across every step of autonomous workflows |
| Failure Mode | Poor output quality despite good instructions | Hallucinations, duplicated work, decisions that contradict actual company architecture |
| Scale Limitation | Hits a wall once agents need cross-tool reasoning or persistent memory | Reusable across all agents, models, and tools - scales with organizational knowledge |
The infrastructure layer most teams haven’t built
Your company’s context already exists. It’s scattered across GitHub repos, Slack threads, Linear tickets, Notion pages, Google Docs, and the heads of people who’ve been around long enough to remember why things were built a certain way. The problem is that none of it is structured for machine consumption.
LangChain’s State of AI Agents report found that performance quality is the top barrier to deploying agents in production, more than twice as significant as cost or safety concerns. Performance quality is largely a context problem: agents perform poorly when they can’t access the right knowledge at the right step.
Most teams try to close this gap by copying raw data into prompts or bolting together quick retrieval scripts. That approach breaks the moment you need agents working across multiple knowledge sources simultaneously. What’s missing is a governed, connected layer that keeps context accurate, permissioned, and retrievable without manual assembly for every single agent interaction.
MCP and the shift to reusable context
Until recently, every agent integration was a custom job. Want your coding agent to read from Jira? Write a connector. Need it to pull from Confluence too? Write another one. Each new tool meant new plumbing, and none of it was portable.
The Model Context Protocol (MCP), originally introduced by Anthropic, changes that equation. MCP provides a standardized interface for AI applications to access external data through a single protocol instead of dozens of bespoke integrations. Instead of hard-wiring each agent to each system, you expose your knowledge through MCP servers that any compatible client can consume.
The architectural implication matters more than the protocol itself. MCP treats context as composable infrastructure: something you build once and reuse across models, agents, and tools. Switch from one LLM provider to another? Your context layer stays intact. Spin up a new agent for a different workflow? It connects to the same knowledge sources through the same interface. Context stops being disposable and starts being durable.
Why knowledge graphs beat vector search for agent context
Vector search does one thing well: finding text chunks that are semantically similar to a query. For simple Q&A, that’s often enough. But agents doing multi-step reasoning need more than similarity. They need to understand how entities relate to each other, when decisions were made, and which documents supersede others.
The gap shows up whenever an agent needs to traverse relationships: “Which services depend on the module that changed in last week’s PR?” That question requires structured connections between code, pull requests, services, and time, not a ranked list of text snippets. Vector search returns the closest paragraphs; it can’t tell you what depends on what.
Knowledge graphs capture those connections explicitly. Instead of returning the three most similar paragraphs, a graph can trace dependencies, surface contradictions, and support the kind of multi-hop reasoning that separates a useful agent from a confident but wrong one.

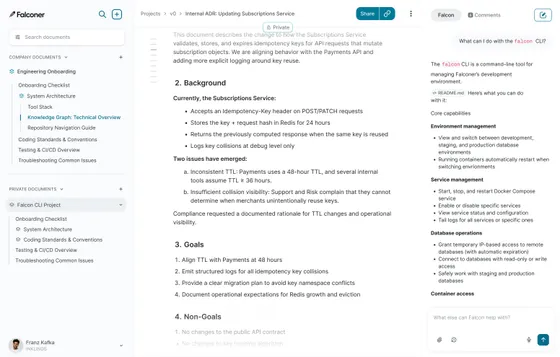
How Falconer turns organizational knowledge into agent context
Everything we’ve covered points to a single bottleneck: someone has to build the context layer. That’s the problem we built Falconer to solve.
Falconer connects to your team’s existing tools (GitHub, Slack, Linear, Notion, Google Drive) and builds a continuously updated knowledge graph linking PRs to docs, decisions to threads, services to owners. When a PR merges, Falconer reads the diff, finds affected docs, and proposes section-scoped edits automatically. Context stays accurate without manual maintenance.
Ask “why did we choose Postgres over DynamoDB?” and Falcon returns the original PR, the Slack thread where it was argued, and the trade-off doc — cited, not hallucinated.
The MCP server reads and writes. When your agent drafts a postmortem mid-incident or updates a runbook to match a config change, that work lands back in Falconer instead of disappearing into a chat window. Every session leaves the knowledge base better than it found it. Most MCPs are read-only; that’s the difference between a search engine and infrastructure that compounds.
The moat was never which model you picked. It’s whether your agents have access to the truth about how your company actually builds software.
That’s what context engineering looks like when it’s solved at the organizational level instead of duct-taped together one prompt at a time.
Context outlasts models
Frontier models change every few months. The next breakthrough is always around the corner. None of it matters if the model doesn’t know how your company actually works.
Models are commoditizing. Context isn’t. A knowledge layer built once on MCP travels with you — Claude this quarter, Gemini next, whatever ships after that. Your context compounds while the models churn.
Final thoughts on the shift from prompts to context
You can perfect your prompts and still watch your agents hallucinate implementation details that contradict your actual architecture. The bottleneck isn’t how you ask, it’s what your agents know going in, which is where context engineering for agents becomes non-negotiable. Connect Falconer to your tools and give your agents the same knowledge your team relies on. Context that compounds across every interaction matters more than any single well-crafted prompt.
FAQ
Context engineering vs prompt engineering: what’s the actual difference?
Prompt engineering optimizes how you ask a question within a single interaction, while context engineering builds the information infrastructure that feeds the model before it ever sees your prompt. Prompt engineering is writing better instructions; context engineering is building the knowledge layer that makes those instructions work across your entire organization.
Can prompt engineering alone power agents at scale?
No. While 79% of enterprises have adopted AI agents, only 11% run them in production, and the gap is largely a context problem. Agents operating without organizational context hallucinate implementation details, recommend abandoned approaches, and generate outputs that ignore your team’s actual architecture and decisions.
What’s the best way to give agents access to company knowledge?
Build a governed context layer that connects your existing tools (GitHub, Slack, Linear, Notion) into a knowledge graph that updates automatically as your code and decisions change. The Model Context Protocol (MCP) provides a standardized interface so any compatible agent can consume this context without custom integrations for every tool.
Context engineering vs RAG: when does vector search fall short?
Vector search returns semantically similar text chunks, but agents doing multi-step reasoning need to understand how entities relate, when decisions were made, and which documents supersede others. Questions like “which services depend on the module that changed in last week’s PR?” require structured connections between code, pull requests, and services, not a ranked list of text snippets. Knowledge graphs handle that traversal; vector search alone doesn’t.
Why do coding agents with good prompts still generate code that conflicts with existing architecture?
The agent has no grounding in your company’s reality: it doesn’t know which services already exist, what approaches your team abandoned, or what decisions happened in last week’s architecture review. The gap is in the memory, not the instructions, and bad context compounds across every step of an autonomous workflow.
What about the docs already in Notion or Confluence?
Falconer imports them automatically — same-day, no manual effort. Existing pages become searchable alongside your code, Slack, and Linear from day one, and Falconer flags gaps, duplicates, and stale content as it ingests.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.
Ready to get started?
Create an account and start building your knowledge base — no contracts or credit card required. Or, contact us to design a custom package for your team.